
Image Processor Terraform Project
In this project, we’ll develop an image processor pipeline using AWS, Terraform, and Python. This pipeline will work as follows: every image uploaded to an S3 bucket will be processed (resized accordingly to a certain shape defined by the user and then converted to black and white) using a Lambda function written in Python, and then the processed image will be saved into another S3 bucket. To successfully tackle this project, you need to have a basic knowledge of Python, AWS (specifically S3 buckets, IAM, and Lambda functions), and Terraform.
Project’s Architecture
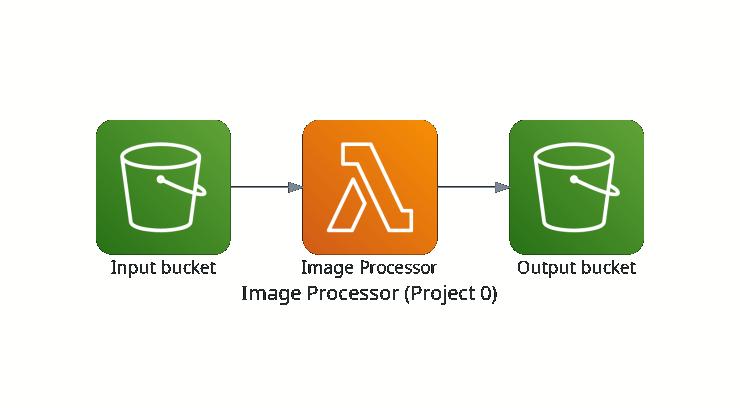
The project’s architecture can be seen in Figure 1. As we briefly described, we’ll have two different S3 buckets: one that will serve as an input folder and the other one as an output folder. Any image uploaded into the input bucket will trigger a Lambda function responsible for loading this image and then processing it (resizing and converting it to a black and white image) using Python, mainly the PIL library. After the processing step and within the lambda function, the preprocessed image will be saved into the output bucket. Despite being an easy, introductory project, we’ll learn a lot of things about AWS and Terraform, such as how to structure a Terraform file and how the AWS components talk to each other.
Development
To create an easy, intuitive step-by-step tutorial, we’ll divide the development part according to the components in the project’s pipeline. Firstly, we’ll talk about the input bucket, such as how to create it, how to set this bucket to private, how to create a trigger for every uploaded image, set the desired permissions, IAM roles, and so on; then, we’ll define the lambda function that will process the images, set the desired permissions, and IAM roles. Finally, we create the output bucket and set it to public.
Input Bucket
To create the input bucket, we use the following code snippet:
resource "aws_s3_bucket" "input_bucket" {
bucket = var.input_bucket_name
force_destroy = true # forces the bucket to be destroyed, even when it's not empty
}And then, we set this bucket to private:
resource "aws_s3_bucket_public_access_block" "input_bucket_policy" {
bucket = aws_s3_bucket.input_bucket.id
block_public_acls = true
block_public_policy = true
}Output Bucket
As we did previously, we create the output bucket using the following code snippet:
resource "aws_s3_bucket" "output_bucket" {
bucket = var.output_bucket_name
force_destroy = true # forces the bucket to be destroyed, even when it's not empty
}And then, we set this bucket to public:
resource "aws_s3_bucket_public_access_block" "output_bucket_policy" {
bucket = aws_s3_bucket.output_bucket.id
block_public_acls = false
block_public_policy = false
}Lambda Function
Now, we must create a Python file for our lambda function, called lambda_function.py, and place the chunk of code below. This code defines a lambda handler that receives an event and a context. We use the event variable to get the bucket and a key, as we need both of these to download the image that triggered the event. Next, we load this image, process it, and then send the processed image to the output bucket.
# Importing the libraries
import boto3
import os
import io
import json
from PIL import Image
s3 = boto3.client("s3")
# Defining the lambda function handler
def lambda_handler(event, context):
bucket = event["Records"][0]["s3"]["bucket"]["name"]
key = event["Records"][0]["s3"]["object"]["key"]
# Checking if it's a valid image type
allowed_extensions = [".jpg", ".jpeg", ".png", ".webp"]
_, ext = os.path.splitext(key.lower())
if ext not in allowed_extensions:
print(f"Skipped unsupported file type: {ext}")
return {
"statusCode": 400,
"body": f"File type {ext} not supported"
}
# Downloading the image from the input bucket
response = s3.get_object(
Bucket=bucket,
Key=key,
)
image_content = response["Body"].read()
# Loading the image and then processing it
try:
image = Image.open(io.BytesIO(image_content))
image = image.resize(
tuple(json.loads(os.environ.get("NEW_IMAGE_SIZE")))
).convert("L") # Resize and convert to black and white
except Exception as e:
return {
"statusCode": 400,
"body": f"Raised error {e} when processing the image!\n"
}
# Uploading the processed image to the output bucket
output_bucket = os.environ.get("OUTPUT_BUCKET")
buffer = io.BytesIO()
image.save(buffer, format="JPEG")
buffer.seek(0)
s3.put_object(
Bucket=output_bucket,
Key=os.path.basename(key),
Body=buffer,
ContentType="image/png",
)
return {
"statusCode": 200,
"body": f"Processed image saved in {output_bucket}/{os.path.basename(key)}!\n"
}Then, we use the following code to create the lambda function in Terraform:
resource "aws_lambda_function" "image_processor" {
function_name = var.lambda_function_name
handler = "lambda_function.lambda_handler"
runtime = "python3.9"
role = aws_iam_role.lambda_role.arn
filename = var.lambda_zipped_file_name
source_code_hash = filebase64sha256(var.lambda_zipped_file_name)
timeout = 30
# Here the define some environment variables that will be used in the Python code
environment {
variables = {
OUTPUT_BUCKET = aws_s3_bucket.output_bucket.bucket
NEW_IMAGE_SIZE = jsonencode(var.new_image_size)
}
}
}So, we are done, right? Not yet! We have to set IAM roles, permissions necessary to run the code, and the S3 trigger when a new image is uploaded into the input bucket. This is exactly what we’ll be doing in the next section.
Trigger, Roles, and Permissions
Alright, so we have defined both buckets and the Lambda function; now we must think about what we need to set to allow the buckets to communicate with the Lambda. Let’s start with the basics: the Lambda function must have access to both S3 (the Lambda must know when an image is uploaded to the input bucket and save the processed image to the output bucket), and we can do that with the following code:
# This code is used to create a new IAM role (called lambda_role) used by Lambda
# and we're going to give the S3 access to this role
resource "aws_iam_role" "lambda_role" {
name = "lambda_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Action = "sts:AssumeRole",
Effect = "Allow",
Principal = {
Service = "lambda.amazonaws.com"
}
}]
})
}# Giving S3 Full Access to the Lambda role we previously created
resource "aws_iam_policy_attachment" "lambda_s3_access" {
name = "lambda_s3_access"
roles = [aws_iam_role.lambda_role.name]
policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess"
}Now that the Lambda has access to both S3 buckets, we must create a trigger in the input bucket so the Lambda function will be triggered whenever a new image is uploaded into the input bucket. First, we must create a new permission for the Lambda function we created so it can invoke from an S3, and we do that with the following code:
resource "aws_lambda_permission" "allow_s3_invocation" {
statement_id = "AllowS3Invoke"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.image_processor.function_name # the Lambda function that will be invoked
principal = "s3.amazonaws.com"
source_arn = aws_s3_bucket.input_bucket.arn # the
}We’ve created an S3 invocation permission for our Lambda function and the input bucket, but we must define what event in the input bucket will trigger this invocation. Since we want this invocation to be triggered whenever an image is uploaded into the input bucket, we must do the following:
resource "aws_s3_bucket_notification" "bucket_notification" {
bucket = aws_s3_bucket.input_bucket.id # setting the input bucket
lambda_function {
lambda_function_arn = aws_lambda_function.image_processor.arn # setting the lambda function that will be triggered
events = ["s3:ObjectCreated:*"] # setting the event (here, whenever a S3 object is created)
}
# this notification depends on the invocation we've created
depends_on = [aws_lambda_permission.allow_s3_invocation]
}Finally, we still need to do one more thing: since the Lambda does not accept a pure Python file, we must zip it. We can also do that with Terraform using the code below:
data "archive_file" "zip_the_lambda_code" {
type = "zip"
source_dir = "${path.module}/lambda_payload" # the source directory that will be zipped
output_path = "${path.module}/${var.lambda_zipped_file_name}" # where the zip file will be saved
}Putting All Together
As we value organization and a well-written code, we’ll create five different Terraform files to place the previous codes: one for the buckets, one for Lambda, one for the provider (in this case, AWS), one for the IAM roles, and, finally, one for the variables.
Create a buckets.tf to put the code that creates both buckets. It will look something like this:
# Creating the S3 input bucket
resource "aws_s3_bucket" "input_bucket" {
bucket = var.input_bucket_name
force_destroy = true
}
resource "aws_s3_bucket_public_access_block" "input_bucket_policy" {
bucket = aws_s3_bucket.input_bucket.id
block_public_acls = true
block_public_policy = true
}
# Creating the S3 output bucket
resource "aws_s3_bucket" "output_bucket" {
bucket = var.output_bucket_name
force_destroy = true
}
resource "aws_s3_bucket_public_access_block" "output_bucket_policy" {
bucket = aws_s3_bucket.output_bucket.id
block_public_acls = false
block_public_policy = false
}Create a lambda.tf to place the code that creates the lambda function and zip it. It will look something like this:
resource "aws_lambda_function" "image_processor" {
function_name = var.lambda_function_name
handler = "lambda_function.lambda_handler"
runtime = "python3.9"
role = aws_iam_role.lambda_role.arn
filename = var.lambda_zipped_file_name
source_code_hash = filebase64sha256(var.lambda_zipped_file_name)
timeout = 30
environment {
variables = {
OUTPUT_BUCKET = aws_s3_bucket.output_bucket.bucket
NEW_IMAGE_SIZE = jsonencode(var.new_image_size)
}
}
}
data "archive_file" "zip_the_lambda_code" {
type = "zip"
source_dir = "${path.module}/lambda_payload"
output_path = "${path.module}/${var.lambda_zipped_file_name}"
}Create a provider.tf to place the code that defines the provider that is going to be used (in our case, it’s the AWS). It will look something like this:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.16"
}
}
}
provider "aws" {
region = var.region
}Create a roles.tf to place the code that creates and sets all roles and permissions. It will look something like this:
resource "aws_iam_role" "lambda_role" {
name = "lambda_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Action = "sts:AssumeRole",
Effect = "Allow",
Principal = {
Service = "lambda.amazonaws.com"
}
}]
})
}
resource "aws_iam_policy_attachment" "lambda_s3_access" {
name = "lambda_s3_access"
roles = [aws_iam_role.lambda_role.name]
policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess"
}
resource "aws_lambda_permission" "allow_s3_invocation" {
statement_id = "AllowS3Invoke"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.image_processor.function_name
principal = "s3.amazonaws.com"
source_arn = aws_s3_bucket.input_bucket.arn
}
resource "aws_s3_bucket_notification" "bucket_notification" {
bucket = aws_s3_bucket.input_bucket.id
lambda_function {
lambda_function_arn = aws_lambda_function.image_processor.arn
events = ["s3:ObjectCreated:*"]
}
depends_on = [aws_lambda_permission.allow_s3_invocation]
}Create a variables.tf to place the code that initializes the necessary variables to execute the project. It will look something like this:
variable "region" {
type = string
default = "us-east-1"
description = "The AWS region."
nullable = true
}
variable "input_bucket_name" {
type = string
description = "The input bucket's name."
nullable = false
}
variable "output_bucket_name" {
type = string
description = "The output bucket's name."
nullable = false
}
variable "lambda_function_name" {
type = string
nullable = false
description = "The lambda function's name."
default = "image_processor"
}
variable "lambda_zipped_file_name" {
type = string
nullable = false
description = "The lambda zipped file's name."
default = "lambda_function_payload.zip"
}
variable "new_image_size" {
type = list(number)
nullable = true
description = "The size of the processed image."
default = [256, 256]
}Finally, all those files must be located in the project’s root folder. As for the Lambda Python code and the requirements (Pillow and boto3) file, it must be placed inside a folder called lambda. The project folder’s structure must look exactly like this:
.
├── buckets.tf
├── lambda
│ ├── lambda_function.py
│ └── requirements.txt
├── lambda.tf
├── provider.tf
├── README.md
├── roles.tf
└── variables.tfYou can also check the code on my GitHub account!
Running the Project
- Set your AWS credentials by running both commands in the terminal:
export AWS_ACCESS_KEY_ID="YOUR_AWS_ACCESS_KEY"
export AWS_SECRET_ACCESS_KEY="YOUR_AWS_SECRET_ACCESS_KEY"- In the root folder, initialize Terraform with the following code:
terraform init- Create a new folder and copy everything that is inside
lambdain it. This folder will be used to zip the Lambda code. So, run the code below:
mkdir lambda_payload && cp lambda/* lambda_payload && cd lambda_payload- Since we’ve set the Python version to be 3.9 in the Lambda function, we must use Python 3 to install the code’s dependencies inside the
lambda_payloadfolder before zipping it. You can do that with the following code:
sudo docker run -v "$PWD":/var/task public.ecr.aws/sam/build-python3.9:latest pip install -r requirements.txt -t . && cd ..- Run Terraform plan and fill in the variables’ values using the terminal:
terraform plan- Lastly, apply all the changes:
terraform planIf you want to destroy and erase everything in AWS, run:
terraform destroy